Terwijl AI oprukt, klampen klantcontactprofessionals zich vast aan ‘empathie’ – dat is immers hetgeen waar mens en software in verschillen? Of ligt dat genuanceerder en wordt het aantal contactcentermedewerkers de komende jaren gedecimeerd? Voor de beantwoording van die vraag duiken we dieper in de werking van AI zoals ChatGPT. Deel 4 van een serie over de betekenis van AI voor klantcontact.
 Kan een chatbot net zo empathisch overkomen als een dokter? “Empathisch zijn is niet voor alle mensen vanzelfsprekend of gemakkelijk. Er wordt de laatste tijd steeds meer onderzoek gedaan naar ‘artificial empathy’,” zegt Art Ligthart, Chief Digital Transformation en partner bij Y.digital.
Kan een chatbot net zo empathisch overkomen als een dokter? “Empathisch zijn is niet voor alle mensen vanzelfsprekend of gemakkelijk. Er wordt de laatste tijd steeds meer onderzoek gedaan naar ‘artificial empathy’,” zegt Art Ligthart, Chief Digital Transformation en partner bij Y.digital.
We spreken met Ligthart (oorspronkelijk IT-architect) over kunstmatige intelligentie of AI. Doel van het gesprek: een duidelijk antwoord op de vraag of AI is staat is (of zal zijn) om empathisch te reageren op klanten. Ligthart begint met te stellen dat AI een verwarrende term is geworden: “Het is nogal een containerbegrip. Er is niet zoiets als ‘de AI-toepassing’.”
AI is een blackbox
“AI is voor veel mensen een blackbox,” aldus Ligthart. “Om er iets van te begrijpen moet je die openmaken. Dan zal je zien dat er allerlei verschillende softwarecomponenten inzitten. Het gaat dus niet om een machine die één bewerking uitvoert, maar om een veelheid aan modules die allemaal een eigen taak hebben. Afhankelijk van de opdracht die je geeft, gaan die onderdelen wel of niet aan het werk. Soms worden bijvoorbeeld drie algoritmes tegelijkertijd ingezet omdat dat handig is. Sommige daarvan zijn volledig uitlegbaar en transparant, andere weer niet. Het ene model is getraind op een gesloten kennisdomein, het andere model werkt op basis van een database en machine learning. Soms worden gegevens opgehaald en in de blackbox verrijkt of wordt de dataset tussentijds bijgesteld.” Ligthart pleit er dan ook voor dat elke organisatie die AI gebruikt de blackbox opent en de onderliggende architectuur beschrijft.
Workflows onder de motorkap
“Ook voor AI in klantcontact geldt dat, direct nadat een toepassing bijvoorbeeld een eerste vraag van een klant heeft gekregen, er meteen al tientallen deelopdrachten kunnen worden uitgevoerd. De eerste module gaat op zoek naar emotie, de tweede naar intent-herkenning, een derde haalt al vast producten uit een database op, een vierde kijkt naar de financiële klantwaarde, een vijfde kijkt naar de contacthistorie in het CRM-systeem, een zesde interpreteert de input van de klant en kijkt op basis van een LLM naar wat de volgende zin zou kunnen zijn. Bij sommige van die deelresultaten wil je misschien tussentijdse controles kunnen uitvoeren. Kortom, onder de motorkap van AI zitten grote aantallen workflows.” Dat geldt overigens ook voor ChatGPT, waar het bepalen van woordvolgorde op basis van waarschijnlijkheid gecombineerd wordt met een aantal andere modellen. [link naar Kennisartikel – Empathie in klantcontact: medewerker versus AI]
Convergentie: combinaties van ‘slimme’ technologie
Die complexiteit in AI neemt alleen maar toe, zegt Ligthart. Dat komt onder andere omdat telkens nieuwe mogelijkheden ontstaan die kunnen worden gecombineerd met de bestaande. Een goed en actueel voorbeeld is ChatGPT, waar inmiddels allerlei nieuwe functionaliteiten ‘bovenop worden gezet’. Denk aan het multimodale AutoGPT, dat met behulp van ChatGPT complexe taken kan uitvoeren zonder menselijke tussenkomst. Veelgenoemd voorbeeld: het programmeren van een app op basis van een prompt van twee woorden: ‘weer’ en ‘app’.
Stapelen en combineren gebeurt dus al. “Als je dat zou doen met deeltoepassingen als emotieherkenning, intent herkenning, analyse van de contacthistorie en klantwaarde en het bepalen van een goede output aan de hand van een LLM, dan kan je een AI-oplossing voor klantcontact realiseren die zeer empathisch overkomt,” aldus Ligthart.
Er zijn nog wel een paar hobbels
Niet alle data die door AI gebruikt wordt, is keurig opgeslagen in databases. “Gestructureerde data zijn lange tijd het uitgangspunt geweest in informatiemanagement. Maar er is steeds meer ongestructureerde data bij gekomen. Denk aan alle gesprekken die we op bij de klantenservice of social media voeren en alle content op internet”, legt Ligthart uit. “Bovendien zitten die data – met verschillen in leeftijd, betrouwbaarheid, betekenis en formats – in allerlei verschillende systemen. Lange tijd hebben informatiespecialisten gedacht dat uitputtend en uniform definiëren van al die begrippen dé oplossing was om zowel data als content goed te kunnen interpreteren. Maar dat sluit helemaal niet aan bij de manier waarop mensen communiceren: als we woorden gebruiken lijken die soms hetzelfde, maar de betekenis kan net iets verschillen. Het concept ‘ondernemer’ betekent binnen de KVK net iets anders dan binnen de Belastingdienst. Alleen al de Belastingdienst heeft zeventig verschillende definities van het begrip loon. Je moet AI-oplossingen uitdenken die hiermee om kunnen gaan.”
LLM alleen is niet voldoende
Credits: WikipediaJayarathina/CC
LLM’s zijn niet goed in het omgaan met verschillende woordbetekenissen – ze werken op basis van immens veel data en brute (en dure) rekenkracht, maar missen het vermogen om goed gebruik te maken van de taal, de woorden en de domeinkennis die binnen organisaties al bestaat en ook al is beschreven. Denk aan vakjargon, woordenboeken of taxonomieën, referentiemodellen, catalogi, gegevensmodellen van data in de systemen, juridische begrippen et cetera.
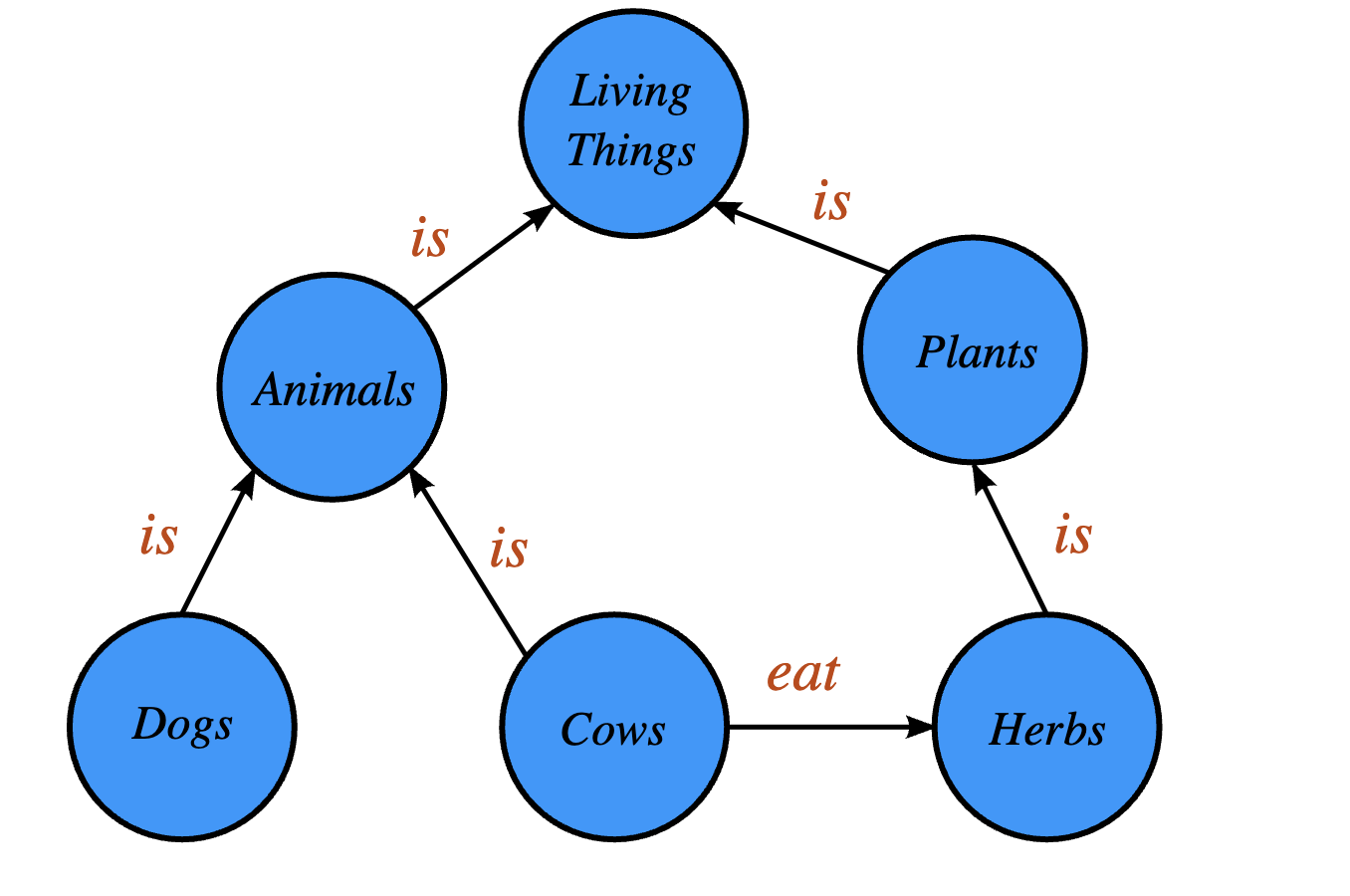
Het ontbrekende puzzelstukje is dan ook een tweede technologie om tot een goede output te komen, zegt Ligthart. “Die technologie is er al een tijdje en wordt aangeduid met ‘knowledge graph’. Hierbij worden begrippen gemodelleerd en worden relaties tussen begrippen gelegd zoals klanten, orders, plaatsen, gebeurtenissen et cetera. Begrippen worden zo in hun context geplaatst. Synoniemen en homoniemen (woorden die er hetzelfde uitzien en hetzelfde klinken, maar een verschillende betekenis hebben – denk aan ‘bank’) kunnen worden gemodelleerd. Begrippen uit customerservice-processen kan je op deze manier bijvoorbeeld verbinden aan juridische begrippen. Ook knowledge graphs leveren dus een taalmodel op, maar dan specifiek van begrippen en hun onderlinge relaties.”
Een semantische laag over alle systemen
Met zo’n taalmodel in je achterzak kun je vervolgens een AI-oplossing maken die de woorden in zowel gestructureerde en ongestructureerde data veel beter kan interpreteren. “Als het woord ‘loon’ wordt gevonden, weet de AI dat er veel verschillende varianten van bestaan, en zal verder kijken naar woorden die volgens de knowledge graph helpen om te bepalen welke specifieke betekenis van ‘loon’ bedoeld wordt. Als de AI op zoek is naar de intent van een klant die belt of chat, dan zal de AI in de knowledge graph kijken en vervolgens relevante vragen stellen om af te leiden welke van de soms honderden intents de klant waarschijnlijk heeft.”
Zo’n taalmodel kan je beschouwen als een semantische laag, waaraan je als gebruiker vragen kunt stellen, zegt Lighart, en die vervolgens gestructureerde en ongestructureerde data raadpleegt om de relevante antwoorden te zoeken. “Zulke taalmodellen maak je altijd in samenwerking met de kennishouders in de organisatie: senior-medewerkers van bijvoorbeeld customerservice, financiën, wet- en regelgeving of operations. En het aardige is trouwens dat LLM’s ook ingezet kunnen worden om te helpen bij het samenstellen van taalmodellen en knowledge graphs uit bestaande data en content. Het is dan wel zaak om die uitkomsten samen met de kennishouders te valideren. Zo ontstaat een ‘enterprise knowledge graph (EKG), die de begrippen en kennis van een organisatie representeert. Zowel de oude data uit alle bestaande systemen als nieuwe data kunnen hiermee worden geïnterpreteerd en verwerkt; de knowledge graph groeit mee door de tijd heen en zal nieuwe begrippen en kennis adopteren.”
LLM + knowledge graph = veelbelovend
“Google is als een van de eerste grote techbedrijven gestart met het gebruiken van knowledge graphs. De knowledge graph die Google heeft opgebouwd, is erg groot, want opgebouwd uit grote delen van het internet. Wordt bij ChatGPT tot nu toe nauwelijks naar betekenis gekeken en vooral naar de waarschijnlijkheid van de woordvolgorde, bij gebruik van knowledge graphs kijkt de software ook naar betekenis van begrippen, relaties, synoniemen en gerelateerde teksten. Het ideaal is een tussenvorm waarbij je beide technieken combineert.”
Die combinatie biedt perspectief voor klantcontact, aldus Ligthart. “Wie van al zijn klantcontacten een knowledge graph zou maken en de belangrijkste intenties in kaart brengt, kan daarna op basis van een klantgesprek vrij snel de intentie achterhalen. Haal de beschikbare data over die klant erbij en maak het gesprek op maat. Combineer dit met emotiedetectie en je kunt een kunstmatige empathische reactie genereren.” En wie hier realtime digitaal vertalen aan toevoegt, heeft het klantcontact van de toekomst klaar, zo zou je kunnen zeggen.
Verborgen intenties blijven een probleem
Dan tot slot de intent herkenning: wat is de vraag van de klant? Of wat is de vraag achter de vraag? Op dit punt acht Ligthart de kans klein dat mensen volledig worden verslagen door machines. Voor software is het lastig om verborgen intenties te herkennen, denk aan sarcasme of dreigementen om op te zeggen, terwijl de klant juist erkenning wil en misschien een goed aanbod.
“Zoals gezegd: als je alle tooling die tot nu toe is ontwikkeld, zou combineren, dan kan je AI-oplossingen realiseren die zeer empathisch overkomen,” zegt Ligthart. “De vraag is natuurlijk of je dat moet willen.” Ofwel: naast allerlei ethische vragen en vragen over validiteit, kwaliteit en beveiliging is er ook de vraag of we vanuit HR- en CX-perspectief ernaar moeten streven om medewerkers te vervangen door geavanceerde AI-oplossingen.
Wat Ligthart betreft is ook de huidige snelheid van de ontwikkelingen een probleem: ”De AI-wereld zet nu de turbo op allerlei toepassingen, maar dus ook op allerlei vormen van nepnieuws en fraude. Dat is een enorme risicofactor. We zitten nu bovenin de hype-fase van Gartner: we moeten er nog achter komen waar en hoe AI succesvol kan worden ingezet. Voor empathie is de gereedschapskist van AI behoorlijk goed gevuld,” besluit Ligthart, “Maar vast staat dat AI-toepassingen wel degelijk het werk van klantcontactmedewerkers gaan raken.” (Ziptone/Erik Bouwer)
Lees ook: “Nederland zou een eigen ‘large language model’ moeten hebben”
Ook interessant
-

Meta heeft een eigen taalmodel ontwikkeld. Het bedrijf zegt hiermee in te spelen op de belangrijkste tekortkoming van de bestaande…
-

ChatGPT trok de afgelopen weken veel aandacht in de media. Kunnen Google, tekstschrijvers en klantcontactmedewerkers naar huis?
-

"AI, ChatGPT en andere geautomatiseerde of selfserviceoplossingen zullen de banen van klantenservicemedewerkers niet laten verdwijnen."